人工無能わけちの学習データをGraphvizでグラフにしてみた
グラフ、面白いよね。棒グラフじゃなくてグラフの方です。
そう、丸と線が繋がって見た目も分かりやすく面白いヤツです。
僕は理系の大学を出ていますが、情報系にしか興味が無かったため、数学の知識は高校レベルです。
電子も数学もちゃんと勉強しておけばよかったよ…。
僕の作った人工無能わけちが学習した連鎖が1300万に到達しました!
圧縮されたバックアップをみると94MB。まだまだ、お手頃なサイズです。
グラフ描画アプリGraphvizを使ってわけちの学習したデータをグラフにしてみよう!
Twitterのみんながよく使う言葉がグラフに現れるはず?
Graphvizはdotという形式で渡す必要があります。以下のような形式。
digraph g {
node [fontname="MSGOTHIC.TTC"];
edge [fontname="MSGOTHIC.TTC"];
"A"->"B";
"B"->"C";
}
何とかしてわけちのデータをこの形式に持って行きます。
わけちのDBはMySQLを使っていて、こんなテーブルで出来ています。
単語と3単語から成る連鎖です。
mysql> desc word; +------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +------------+--------------+------+-----+---------+----------------+ | WORD_ID | bigint(20) | NO | PRI | NULL | auto_increment | | POS_ID | bigint(20) | YES | | NULL | | | word | varchar(255) | YES | MUL | NULL | | | WORD_COUNT | int(11) | YES | | NULL | | | TIME | int(11) | YES | | NULL | | +------------+--------------+------+-----+---------+----------------+ 5 rows in set (0.00 sec) mysql> desc chain; +----------+------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +----------+------------+------+-----+---------+----------------+ | CHAIN_ID | bigint(20) | NO | PRI | NULL | auto_increment | | PREFIX01 | bigint(20) | YES | MUL | NULL | | | PREFIX02 | bigint(20) | YES | MUL | NULL | | | SUFFIX | bigint(20) | YES | MUL | NULL | | | START | tinyint(1) | YES | | NULL | | +----------+------------+------+-----+---------+----------------+ 5 rows in set (0.00 sec)
まずは、タブ区切りで出力して。
僕は一時的に出力したよ、という意味でoutを使う癖があります。アウト!
tmp、bak、orgに次ぐ、なかなかいいネーミングだと思うんだけど、僕しか使ってる人を見たことがない。
select word1.word, word2.word, word3.word from chain inner join word word1 on word1.word_id = chain.prefix01 inner join word word2 on word2.word_id = chain.prefix02 inner join word word3 on word3.word_id = chain.suffix limit 100000 INTO OUTFILE "/tmp/out.tsv" FIELDS TERMINATED BY '\t';
良さそうだ。
み ない 場合 ない 場合 、 場合 、 怒ら 、 怒ら れ 怒ら れ ない れ ない よう よう に 残業 に 残業 し 残業 し てる てる のに 時間
やっつけスクリプトで変換してみました。たまにはpythonで。
(使い捨てです。こんなスクリプトを本番で使っちゃだめですよ!)
#!/usr/bin/python
# coding: UTF-8
import sys
f = open(sys.argv[1]);
print "digraph g {"
print " node [fontname=i\"MSGOTHIC.TTC\"];"
print " edge [fontname=\"MSGOTHIC.TTC\"];"
line = f.readline()
while line:
words = line.rstrip().split("\t")
print " \"" + words[0] + "\"->\"" + words[1] + "\";"
print " \"" + words[1] + "\"->\"" + words[2] + "\";"
line = f.readline()
f.close
print "}"
早速食わせる。
python tsv2dot.py /tmp/out.tsv > ./out.tsv.dot
そして、Graphvizをインストールして実行します。
-Kでどんなレイアウトにするか指定できます。
今回は放射状のレイアウトであるtwopiにしてみた。
sudo yum install graphviz graphviz-gd dot -Ktwopi -Tpng out.tsv.dot -o g.png
そして…。

このロリコンどもめ!!
右上に孤立しているのは何だろう?
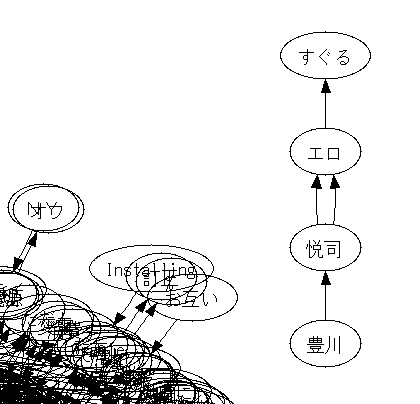
クソワロタwwwwwwwww
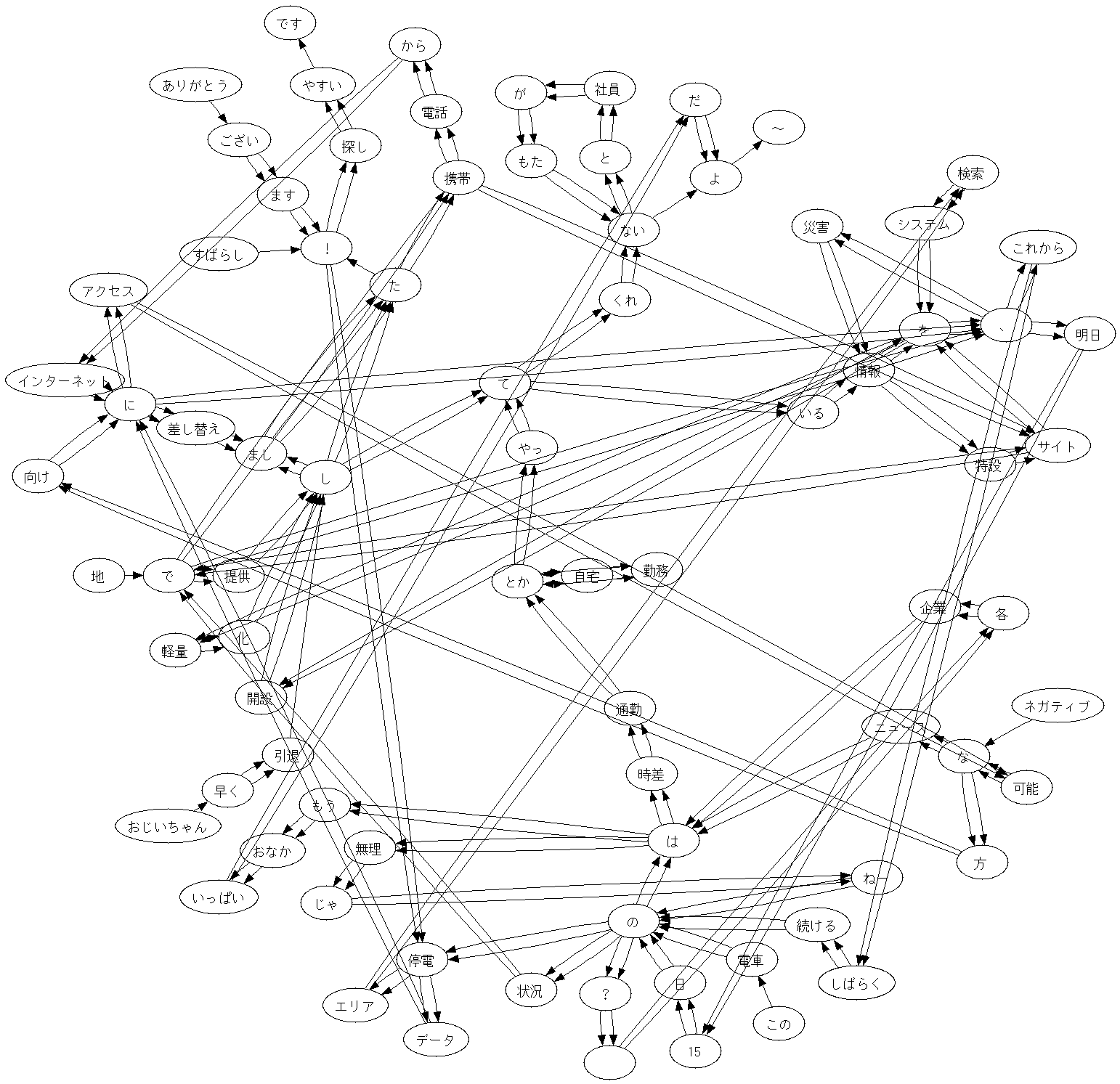
100サンプルの例。意図した結果が得られたような…?
Graphvizがどんなもんかがわかって、はなまる、ということで、おやすみなさい。
後から気づいたけど、単純に連鎖を学習させると重複が出るので線がダブっちゃってますね…。
<h3>20151203</h3>
2200万 chains!
neologdパワー恐るべし!